《R数据科学》高清中/英文版PDF+源代码



内容提要
本书的目标是教会读者使用最重要的数据科学工具,从而为实施数据科学奠定坚实的基础。读完本书后,你将掌握R语言的精华,并能够熟练使用多种工具来解决各种数据科学难题。每一章都按照这样的顺序组织内容∶ 先给出一些引人入胜的示例,以便你可以整体了解这一章的内容,然后再深入细节。本书的每一节都配有习题,以帮助你实践所学到的知识。
本书适合R数据科学家阅读。
前言
数据科学是一门激动人心的学科,它可以将原始数据转化为认识、见解和知识。本书的目标是帮助你学习使用 R语言中最重要的数据科学工具。读完本书后,你将掌握 R 语言的精华,并能够熟练使用多种工具来解决各种数据科学难题。
你将学到什么
数据科学是一个极其广阔的领域。仅靠一本书是不可能登堂入室的。本书的目标是教会你使用最重要的数据科学工具。在一个典型的数据科学项目中,需要的工具模型大体如下图所示。
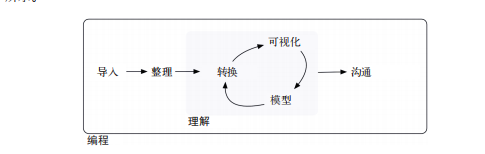
首先,你必须将数据导入 R。这实际上就是读取保存在文件、数据库或 Web API 中的数据,再加载到R 的数据框中。如果不能将数据导入 R,那么数据科学就根本无从谈起。
导入数据后,就应该对数据进行整理。数据整理就是将数据保存为一致的形式,以满足其所在数据集在语义上的要求。简而言之,如果数据是整洁的,那久每列都是一个变量。每行都是一个观测。整洁的数据非常重要,因为一致的数据结构可以让你将工作重点放在与数据有关的问题上,而不用再费尽心思地将数据转换为各种形式以适应不同的函数。
一旦拥有了整洁的数据,通常下一步就是对数据进行转换。数据转换包括选取出感兴趣的观测(如居住在某个城市里的所有人,或者去年的所有数据)、使用现有变量创建新变量(如根据距离和时间计算出速度),以及计算一些摘要统计量(如计数或均值)。数据整理和数据转换统称为数据处理。
一旦使用需要的变量完成了数据整理,那么生成知识的方式主要有两种∶可视化与建模。这两种方式各有利弊,相辅相成。因此,所有实际的数据分析过程都要在这两种方式间多次重复。
可视化本质上是人类活动。良好的可视化会让你发现意料之外的现象,或对数据提出新的问题。你还可以从良好的可视化中意识到自己提出了错误的问题,或者需要收集不同的数据。可视化能够带给你惊喜,但不要期望过高,因为毕竞还是需要人来对其进行解释。模型是弥补可视化缺点的一种工具。如果已经将问题定义得足够清晰,那么你就可以使用—个模型来回答间题。因为模型本质上是—种数学工具或计算工具。所以它们的扩展性一般非常好。即使扩展性出现问题,购买更多计算机也比雇用更多聪明的人便宜!但是每个模型都有前提假设,而且模型本身不会对自己的前提假设提出疑问,这就意味着模型本质上不能给你带来惊喜。
数据科学的最后一个步骤就是沟通。对于任何数据分析项目来说,沟通绝对是一个极其重要的环节。如果不能与他人交流分析结果,那么不签模型和可视化让你对数每理解得多么透彻,这都是没有任何实际意义的。
围绕在这些技能之外的是编程。编程是贯穿数据科学项目各个环节的一项技能。数据科学家不一定是编程专家,但掌握更多的编程技能总是有好处的,因为这样你就能够对日常任务进行自动处理,并且非常轻松地解决新的问题。
你将在所有的数据科学项目中用到这些工具,但对干多数项目来说,这些工具还不够。这大致符合 80/20定律∶你可以使用从本书中学到的工具来解决每个项目中 80% 的问题,但你还需要其他工具来解决其余 20% 的问题。我们将在本书中为你提供资源,让你能学到更多的技能。
本书的组织结构
前面对数据科学工具的描述大致是按照我们在分析中使用它们的顺序来组织的(尽管你肯定会多次使用它们)。然而,根据我们的经验,这并不是学习它们的最佳方式,具体原因如下。
· 从数据导入和数据整理开始学习并不是最佳方式,因为对于导入和整理数据来说,80%的时间是乏味和无聊的,其余 20%的时间则是诡异和令人沮丧的。在学习一项新技术时,这绝对是一个糟糕的开始!相反,我们将从数据可视化和数据转换开始,此时的数据已经导入并目是整理完毕的。这样—来,当导入和整理自己的数据时,你就会始终保持高昂的斗志,因为你知道这种痛苦终有回报。
·有些主题最好结合其他工具来解释。例如,如果你已经了解可视化、数据整理和编程,那么我们认为你会更容易理解模型是如何工作的。
·编程工具本身不一定很有趣,但它们确实可以帮助你解决更多非常困难的问题。在本书的中间部分,我们会介绍一些编程工具,它们可以与数据科学工具结合起来以解决非常有趣的建模问题。
我们尽量在每一章中使用同一种模式∶先给出一些引人入胜的示例,以便你大体了解这一章的内容,然后再深入细节。本书的每一节都配有习题,以帮助你实践所学到的知识。虽然跳过这些习题是个非常有诱惑力的想法,但使用真实问题进行练习绝对是最好的学习方式。
本书未包含的内容
本书并未涉及一些重要主题。我们深信,重要的是将注意力坚定地集中在最基本的内容上,这样你就可以尽快入门并开展实际工作。这也就是说,本书不会涵盖每一个重要主题。
大数据
本书主要讨论那些小规模的、能够驻留在内存中的数据集。这是开始学习数据科学的正确方式,因为只有处理过小数据集,你才能处理大数据集。你从本书中学到的工具可以轻松地处理几百兆字节的数据,处理1-2 GB 的数据也不会有什么大问题。如果你的日常工作是处理更大的数据(如 10~100 GB),那么你应该更多地学习一下 data.table(https∶//github. com/Rdatatable/datatable)。本书不会介绍 data.table,因为它的界面太过简洁,几平没有语言提示,这使得学习起来很困难。但是如果你需要处理大数据,为了获得性能 上的回报。多付出一些努力来学习它还是值得的。
如果你的数据比这还大,那么就需要仔细思考—下了,这个大数据向题是否其穿献是—个小数据问题。虽然整体数据非常大,但回答特定问题所需要的数据通常较小。你可以找出一个子集、子样本或者摘要数据,该数据既适合在内存中处理,又可以回答你感兴趣的问间题。此时的挑战就是如何找到合适的小数据,这通常需要多次迭代。
另外一种可能是,你的大数据问题实际上就是大量的小数据问题。每一个问题都可以在内存中处理,但你有数百万个这样的问题。举例来说,假设你想为数据集中的每个人都拟合一个模型。如果只有10 人或 100 人,那这是小菜一碟,但如果有 100万人,情况就完全不同了。好在每个问题都是独立于其他问题的(这种情况有时称为高度并行, embarrassingly parallel),因此你只需要一个可以将不同数据集发送到不同计算机上进行处理的系统(如 Hadoop 或 Spark)即可。如果已经知道如何使用本书中介绍的工具来解决独立子集的问题,那么你就可以学习一下新的工具(比如 sparklyr、rhipe 和 ddr)来解决整个数据集的问题。
Python、Julia以及类似的语言
在本书中,你不会学到有关 Python、Julia 以及其他用于数据科学的编程语言的任何内容。这并不是因为我们认为这些工具不好,它们都很不错!实际上,多数数据科学团队都会使用多种语言,至少会同时使用 R 和 Python。
但是,我们认为最好每次只学习并精通一种工具。如果你潜心研究一种工具,那么会比同时泛泛地学习多个工具掌握得更快。这并不是说你只应该精通一种工具,而是说每次专注于一件事情时,通常你会进步得更快。在整个职业生涯中,你都应该努力学习新事物,但是一定要在充分理解原有知识后,再去学习感兴趣的新知识。
我们认为 R是你开始数据科学旅程的一个非常好的起点,因为它从根本上说就是一种用来支持数据科学的环境。R 不仅仅是一门编程语言,它还是进行数据科学工作的一种交互式环境。为了支持交互性,R 比多数同类语言灵活得多。虽然会导致一些缺点,但这种灵活性的一大好处是,可以非常容易地为数据科学过程中的某些环节量身定制语法。这些微型语言有助于你从数据科学家的角度来思考问题,还可以在你的大脑和计算机之间建立流畅的交流方式。
非矩形数据
本书仅关注矩形数据。矩形数据是值的集合,集合中的每个值都与一个变量和一个观测相关。很多数据集天然地不符合这种规范,比如图像、声音、树结构和文本。但是矩形数据框架在科技与工业领域是非常普遍的。我们认为它是开始数据科学旅途的一个非常好的起点。
假设验证
数据分析可以分为两类;假设生成和假设验证(有时称为验证性分析)。无须掩饰,本书的重点就在于假设生成,或者说是数据探索。我们将对数据进行深入研究,并结合专业知识生成多种有趣的假设来帮助你对数据的行为方式作出解释。你可以对这些假设进行非正式的评估,凭借自己的怀疑精神从多个方面向数据发起挑战。假设验证与假设生成是互补的。假设验证比较困难,原因如下。
● 你需要一个精确的数学模型来生成可证伪的预测,这通常需要深厚的统计学修养。
●为了验证假设,每个观测只能使用一次。一旦使用观测的次数超过了一次,那么就回到了探索性分析。这意味着,若要进行假设验证,你需要"预先注册"(事先拟定好) 自已的分析计划,而且看到数据后也不能改变计划。在本书的第四部分中,我们将讨论一些相关的策略,你可以使用它们让假设验证变得更容易。
经常有人认为建模是用来进行假设验证的工具,而可视化是用来进行假设生成的工具。这种简单的二分法是错误的;模型经常用于数据探索;只需稍作处理,可视化也可以用来进行假设验证。核心区别在于你使用每个观测的频率;如果只用一次,那么就是假设验证;如果多于一次,那么就是数据探索。
准备工作
为了最有效地利用本书,我们对你的知识结构做了一些假设。你应该具有一定的数学基础,如果有一些编程经验也会有所帮助。如果从来没有编写过程序,那么你应该学习一下 Garrett 所著的《R 语言入门与实践》',它可以作为本书的有益补充。
为了运行本书中的代码,你需要4个工具;R、RStudio、一个称为tidyyerse的R包集合,以及另外几个R 包。包是可重用 R 代码的基本单位,它们包括可重用的函数、描述函数使用方法的文档以及示例数据。
R
可以在 CRAN(comprehensive R archive network)下载 R。CRAN由分布在世界各地的很多镜像服务器组成,用于分发 R 和 R 包。不要尝试选择离你近的服务器,而应该使用云镜像∶ https∶//cloud.r-project.org,它会自动找出离你最近的服务器。
R 的主版本—年发布一次,每年也会发布两三个次版本,因此你应该定期更新。更新 R有一点麻烦,特别是更新主版本会要求你重新安装所有的 R 包,但是如果不更新的话,麻烦会更多。
RStudio
RStudo 是用于R 编程的一种集成开发环境(integrated development environment,IDE)。
RStudio 每年会更新多次。当有新版本时, RStudio 会进行通知。应该定期更新,这样你就可以使用其最新、最强大的功能。为了运行本书中的代码,请确认安装了RStudio 1.0.0。
【下载地址】
链接:https://pan.baidu.com/s/1fVrCpZAMcB2gLfbR2aRpSA
提取码:l0ed
相关文章
为了更好地适应新形势,满足读者对大数据分析处理学习的迫切需要,我们推出了《大数据分析 ∶ R基础及应用》一书 ,力求使读者能够从中了解大数据
读完本书后,你将掌握R语言的精华,并能够熟练使用多种工具来解决各种数据科学难题。
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始, 获得初始
通过它,你将学到如何写能处理大量非结构化文本的 Python 程序。你将获得有丰富标注的涵盖语言学各种数据结构的数据集,而且你将学到分析书面
本书可以作为Python编程语言的一本指南或者教程。它主要是为新手而设计,不过对于有经验的程序员来说,它同样有用。
本书以机器学习与计算统计为主题背景,专门讲t述如何挖掘和分析 Web,上的数据和资源,如何分析用户体验、市场营销、个人品味等诸多信息,并得出
为了能让更多的编程小自轻松地入门编程,我把高效学习法结合 Pvthon 中的核心知识,写成了这本书。随意翻上几页,你就会发现这本书和其他编程
本书结构非常简单,其实就是 52 个习题。其中 26 个覆盖了输入输出、变量、以及函数三个课题,另外 26个覆盖了一些比较高级的话题,如条件
本书以CPython为研究对象,在C代码一级,深入细致地剖析了Python的实现。本书不仅包括了对大量Python内置对象的剖析,更将大量的
本书是学习Python编程语言的入门书籍。Python是一种很流行的开源编程语言,可以在各种领域中用于编写独立的程序和脚本。Python免费
本书用 Python 语言来讲解算法的分析和设计。本书主要关注经典的算法,但同时会为读者理解基本算法问题和解决问题打下很好的基础。全书共 1
本书面向的读者是那些经常使用电子表格软件进行数据处理,但从未写过一行代码的人。前几章会教你设置 Python 运行环境,告诉你计算机是如何看
神经网络是一种模拟人脑的神经网络,以期能够实现类人工智能的机器学习技术。本书揭示神经网络背后的概念,并介绍如何通过Pvthon实现神经网络。
Python 是一种容易学习的强大的编程语言。它包含了高效的高级数据结构,能够用简单而高效的方式进行面向对象编程。Python 优雅的语法和
本书是面向 Python 初学者的学习指南,详细介绍了 Python 编程基础,以及一些高级概念,如面向对象编程。
FlashFXP绿色版网盘下载,附激活教程 3464
FlashFxp百度网盘下载链接:https://pan.baidu.com/s/1MBQ5gkZY1TCFY8A7fnZCfQ。FlashFxp是功能强大的FTP工具
Adobe Fireworks CS6 Ansifa绿色精简版网盘下载 3398
firework可以制作精美或是可以闪瞎眼的gif,这在广告领域是需要常用的,还有firework制作下logo,一些原创的图片还是很便捷的,而且fireworks用法简单,配合dw在做网站这一块往往会发挥出很强大的效果。百度网盘下载链接:https://pan.baidu.com/s/1fzIZszfy8VX6VzQBM_bdZQ
navicat for mysql中文绿色版网盘下载 2993
Navicat for Mysql是用于Mysql数据库管理的一款图形化管理软件,非常的便捷和好用,可以方便的增删改查数据库、数据表、字段、支持mysql命令,视图等等。百度网盘下载链接:https://pan.baidu.com/s/1T_tlgxzdQLtDr9TzptoWQw 提取码:y2yq
火车头采集器(旗舰版)绿色版网盘下载 3226
火车头采集器是站长常用的工具,相比于八爪鱼,简洁好用,易于配置。火车头能够轻松的抓取网页内容,并通过自带的工具对内容进行处理。站长圈想要做网站,火车头采集器是必不可少的。百度网盘链接:https://pan.baidu.com/s/1u8wUqS901HgOmucMBBOvEA
Photoshop(CS-2015-2023)绿色中文版软件下载 3209
安装文件清单(共46G)包含Window和Mac OS各个版本的安装包,从cs到cc,从绿色版到破解版,从安装文件激活工具,应有尽有,一次性打包。 Photoshop CC绿色精简版 Photoshop CS6 Mac版 Photoshop CC 2015 32位 Photoshop CC 2015 64位 Photoshop CC 2015 MAC版 Photoshop CC 2017 64位 Adobe Photoshop CC 2018 Adobe_Photoshop_CC_2018 Photoshop CC 2018 Win32 Photoshop CC 2018 Win64